Mastering the Art of Solving Machine Learning Problems: The Ultimate Step-by-Step Guide (Part 2)

Welcome to Part 2 of our quest to master the art of solving machine learning problems!
In the previous section, we covered the essential steps of problem understanding, problem definition, and data gathering and preparation. [Refer : Mastering the Art of Solving Machine Learning Problems: The Ultimate Step-by-Step Guide (Part 1)]
Now, we’re ready to embark on the next phase of our journey, where we will focus on transforming the prepared data into meaningful insights and deploying our machine learning models into real-world scenarios.
In this section, we will explore three key steps: model development and evaluation, model selection and optimisation, and model deployment and maintenance.
These steps will take us from the realm of experimentation to the realm of practical implementation, ensuring that our machine learning solutions deliver tangible value and impact. So, fasten your seatbelts and get ready to dive in!
Step 4: Model Selection and Training
This step involves choosing an appropriate machine learning algorithm or model architecture and training it on the prepared data to learn patterns and make predictions. Just as an artist carefully selects the right brush and canvas for a masterpiece, selecting the right model is crucial for achieving accurate and reliable results.

Here’s a breakdown of the key aspects involved in model selection and training:
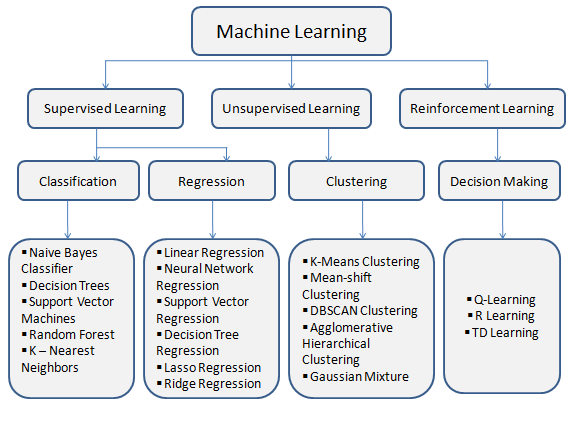
- Understanding Different Model Types: Machine learning offers a diverse range of models, each with its strengths and limitations. These include decision trees, support vector machines (SVM), random forests, neural networks, and many more. It’s essential to have a good understanding of the characteristics, assumptions, and capabilities of various models to choose the most suitable one for your problem. Consider factors such as the nature of the data, the complexity of the task, interpretability requirements, and available computational resources.
2. Evaluating Model Performance Metrics: To assess the effectiveness of a model, you need to define appropriate performance metrics. Common metrics for classification tasks include accuracy, precision, recall, F1 score, and area under the receiver operating characteristic curve (AUC-ROC). For regression tasks, metrics like mean squared error (MSE), root mean squared error (RMSE), and R-squared are commonly used. Select the metrics that align with your problem objectives and evaluate model performance accordingly.

3. Hyperparameter Tuning: Models often have hyperparameters that need to be set before training. These parameters control the behaviour and complexity of the model. Examples include the learning rate in neural networks, the depth of a decision tree, or the regularisation strength in linear models. Hyperparameter tuning involves searching for the optimal combination of hyperparameters to maximise model performance. Techniques such as grid search, random search, or Bayesian optimisation can help in this process.

4. Training and Validation: Once the model and hyperparameters are selected, it’s time to train the model on the training data. The model learns from the patterns in the data and adjusts its internal parameters to minimise the chosen objective function (e.g., minimising the loss function in supervised learning). It’s crucial to monitor the model’s performance during training to ensure it doesn’t overfit (perform well on the training data but poorly on unseen data) or under-fit (fail to capture the underlying patterns). Validation data is used to evaluate the model’s performance during training and guide any necessary adjustments.
5. Regularisation and Cross-Validation: Regularisation techniques such as L1 or L2 regularisation can be applied to prevent overfitting and improve model generalisation. Regularisation adds a penalty term to the loss function, discouraging the model from learning overly complex patterns. Cross-validation is another important technique to assess model performance and reduce the dependence on a single training-validation split. It involves dividing the data into multiple folds, training the model on different fold combinations, and evaluating performance across all folds to get a more robust estimate of model performance.
Let’s continue with our sentiment analysis example from Part 1, to understand the significance of model selection and training. After preparing the data, you decide to choose a neural network model, specifically a Long Short-Term Memory (LSTM) network, known for its effectiveness in processing sequential data. You select appropriate performance metrics such as accuracy, precision, and recall to evaluate the model’s sentiment prediction. Through hyperparameter tuning, you experiment with different learning rates, batch sizes, and LSTM layer configurations to find the optimal settings. During training, you closely monitor the model’s loss on the training and validation sets to prevent overfitting or under-fitting. Regularisation techniques like dropout are applied to improve generalisation, and cross-validation is employed to obtain a reliable estimate of the model’s performance.
Remember! Model selection and training is an iterative process. It requires experimentation, evaluation, and fine-tuning to find the optimal model configuration that yields the best results for your specific problem.
Step 5: Evaluating and Fine-tuning the Model
This step involves assessing the performance of the trained model, identifying areas of improvement, and iteratively refining the model to achieve better results. Just like a sculptor who meticulously chisels away at their work to create a masterpiece, evaluating and fine-tuning the model allows us to shape and optimise its performance.
Here’s a breakdown of the key aspects involved in evaluating and fine-tuning the model:
1. Performance Evaluation Metrics: To measure the effectiveness of the model, you need to choose appropriate evaluation metrics that align with your problem domain. For classification tasks, metrics such as accuracy, precision, recall, F1 score, and AUC-ROC are commonly used. Regression tasks often employ metrics like mean squared error (MSE), root mean squared error (RMSE), and R-squared. Selecting the right metrics helps you assess the model’s performance objectively and make informed decisions during the fine-tuning process. [For more details about metrics, refer : The art of assessing Machine Learning (ML) models]

2. Error Analysis: Understanding the model’s errors is crucial for identifying patterns and areas of improvement. By analysing misclassified instances or instances with high prediction errors, you gain insights into the limitations of the model and potential data issues. For example, in a sentiment analysis task, analysing misclassified samples can reveal patterns related to specific phrases or contexts that the model struggles to capture accurately. This analysis helps you refine the model by addressing the identified shortcomings.
3. Hyperparameter Fine-tuning: Fine-tuning the model involves adjusting the hyperparameters to improve its performance. This process builds upon the initial hyperparameter tuning performed during model selection and training. Based on the insights gained from error analysis and performance evaluation, you can make targeted changes to the hyperparameters. This could involve experimenting with different learning rates, regularisation strengths, network architectures, or other model-specific parameters. The goal is to find the optimal combination of hyperparameters that enhances the model’s performance and generalisation capabilities.
4. Ensemble Methods: Ensemble methods offer a powerful technique to further boost model performance. By combining multiple models, each with its unique strengths and weaknesses, you can create a more robust and accurate prediction. Ensemble methods include techniques like bagging, boosting, and stacking. For instance, in a classification task, you can train several models, such as random forests or support vector machines, and combine their predictions through voting or weighted averaging. Ensemble methods help to mitigate individual model biases and enhance overall performance.

5. Cross-Validation and Test Set Evaluation: To obtain a reliable estimate of the model’s performance, it’s essential to evaluate it on unseen data. Cross-validation, as mentioned earlier, provides a robust evaluation by splitting the data into multiple folds and training the model on different fold combinations. However, it’s also crucial to reserve a separate test set, completely unseen by the model during training and validation. This test set serves as the final evaluation benchmark and helps assess the model’s performance in real-world scenarios.

Let’s revisit our sentiment analysis example to understand the significance of evaluating and fine-tuning the model. After training the LSTM model on the sentiment analysis task, you evaluate its performance using metrics like accuracy, precision, and recall. Upon analysing the model’s errors, you discover specific patterns related to certain phrases that the model struggles to classify accurately. Armed with this insight, you fine-tune the model by adjusting hyperparameters like the learning rate and embedding dimension to improve its performance on these challenging instances. Additionally, you explore ensemble methods by combining multiple models and observe a significant boost in prediction accuracy. Finally, you evaluate the model on a separate test set to ensure its real-world performance aligns with your expectations.
Remember, the process of evaluating and fine-tuning the model is iterative. It requires careful analysis, experimentation, and a willingness to adapt and iterate based on the observed results. By continuously refining your model through this step, you can unlock its full potential and achieve the desired performance.
Step 6: Deploying and Maintaining the Model
Congratulations! You’ve reached the final step in our journey of mastering the art of solving machine learning problems. Step 6 focuses on deploying and maintaining the model, ensuring that it seamlessly transitions from the development phase to a production environment. This step is crucial for making your machine learning solution practical, scalable, and sustainable over time.
Let’s dive into the key aspects involved in deploying and maintaining the model:
1. Deployment Infrastructure: Deploying a machine learning model requires setting up the necessary infrastructure to serve predictions efficiently. Depending on your specific requirements, you might consider deploying the model on cloud platforms like AWS, Azure, or Google Cloud, or even on-premises infrastructure. Designing a scalable and robust infrastructure that can handle prediction requests in real-time or batch processing is essential for a successful deployment.

2. API Development: To interact with the deployed model, you need to design an application programming interface (API) that exposes endpoints for making predictions. The API acts as a bridge between the model and the applications or systems that require its predictions. Using frameworks like Flask, Django, or FastAPI, you can develop a RESTful API that accepts input data, performs the necessary preprocessing, and returns the model’s predictions. This enables seamless integration of the model into different software applications or systems.

3. Monitoring and Performance Tracking: Once the model is deployed, it’s crucial to monitor its performance and track its behaviour in real-world scenarios. Implementing monitoring tools and techniques allows you to identify potential issues, such as model drift or degradation in performance, and take proactive measures to address them. Monitoring also helps ensure that the model continues to provide accurate and reliable predictions as the underlying data or business requirements evolve over time.
4. Versioning and Model Updates: Machine learning models are not static entities but evolve as new data becomes available or as new techniques and algorithms emerge. Implementing a robust versioning system enables you to keep track of different iterations of the model, making it easier to roll back to previous versions if needed. Additionally, regularly updating the model with new data or retraining it with improved algorithms allows you to continually enhance its performance and adapt to changing business needs.

5. Security and Privacy Considerations: Deploying a machine learning model requires careful attention to security and privacy aspects. Depending on the nature of the data and the use case, you may need to implement measures to protect sensitive information, ensure secure communication channels, and comply with data protection regulations. This includes techniques like encryption, access control, and anonymisation to safeguard both the model and the data it processes.
6. Documentation and Knowledge Transfer: As the model moves into production, maintaining comprehensive documentation becomes vital. Documenting the model’s architecture, dependencies, data preprocessing steps, and API specifications helps ensure proper knowledge transfer and facilitates troubleshooting or future updates. Clear and concise documentation also enables collaboration among team members and simplifies the onboarding process for new stakeholders.

7. Regular Maintenance and Model Retraining: Machine learning models are not set-and-forget solutions. Regular maintenance is necessary to ensure their continued effectiveness and relevance. This includes periodic model evaluation, retraining with new data, and fine-tuning based on ongoing performance analysis. By keeping the model up-to-date, you can maximise its accuracy, adapt to changing patterns or trends, and optimise its performance over time.
To put this step into perspective, let’s consider our sentiment analysis example.

After fine-tuning the LSTM model, you deploy it on a scalable cloud infrastructure, setting up an API that allows other applications to interact with the model and obtain sentiment predictions in real-time. You establish monitoring mechanisms to track the model’s performance, detecting any drift or degradation in accuracy. Additionally, you implement versioning to manage different iterations of the model and plan for regular updates to account for changes in language usage or sentiment patterns.
By successfully deploying and maintaining your machine learning model, you ensure its long-term value, reliability, and usability. It becomes an integral part of the systems and applications that rely on its predictions, contributing to informed decision-making and driving positive outcomes. [For more details on how to leverage MLOps for deploying and maintaining models, refer: Unlocking Success with MLOps]
With Step 6 completed, you have gained a comprehensive understanding of the entire process of solving machine learning problems, from problem understanding to model deployment. Following these steps and leveraging domain expertise, you can navigate the complexities of machine learning projects and achieve impactful results.
Remember, mastering the art of solving machine learning problems is a continuous journey of learning, experimentation, and improvement. Embrace the iterative nature of machine learning, continuously learn from your experiments, and refine your approach. With a structured methodology and a mindset of curiosity and exploration, you’ll unlock the true potential of machine learning in solving complex real-world challenges. So, are you ready to tackle your next machine learning problem?
